-
要能采集网址的火车头,必须是7版以上的,以下的版本无法办到。
首先创建一个标签为本文网址,勾选后面的“从网址中采集”。
选择下面的“正则提取”,点击通配符“(??)”,这样在窗口中就显示为(?[\s\S]*?)
我们再在它前加一个与字符串开始的地方匹配的符号^,又在它后面加一个与字符串结束的地方匹配的符号$,这样就变成了^(?[\s\S]*?)$。如图:
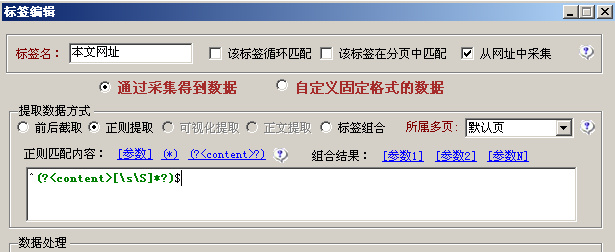
我们来解释下意思
Content 代表内容
? 表示匹配0次或者1次
\s 匹配所有空白字符
\S 匹配所有非空白字符
* 修饰匹配次数为 0 次或任意次本文由本站原创或投稿者首发,转载请注明来源!
本文链接:http://www.ziti66.com/net/html/69.html
-
<< 上一篇下一篇 >>
说说用火车采集器怎样采集当前文章的url网址
人参与 2022年10月18日 09:17 分类 : 网站优化 点这评论

祖国加油,相信新的一年会更好...
森林防火,人人有责。祖国加油...
搜索
-
网站分类
-
Tags列表
-
最新留言
-
++发现更多精彩++
-
-
海内存知己,天涯若比邻。
 黔ICP备2020011602号-8
黔ICP备2020011602号-8 贵公安备52052602000222号
贵公安备52052602000222号